- Verbal aggression for profit and fun
- ‘DIF plots again: A correction’
- Trying to extend DIF plots
- Minorization and the 2PL
- Psychometric woes (with the 2PL in particular)
- Just a Linux rant
- Simulating data from the interaction model
- When CML is not possible
- Simulating data with dexter: a commented example
- Approximate survey errors for the correlation and the standard deviation: with R package survey
- Classical Test Theory with IRT
- And have you seen the Rasch sampler?
- Analyzing continuous responses with dexter
- Hot on the Trail of Warm
- Round about SVD
- The information game
- Calculating the score distribution given ability
- Local (in)dependence and polytomization
- My (more or less coherent) views on model fit
- My perennial Slide 1
- Aspects of the aspect ratio
- ‘Visualising Differential Item Pair Functioning: The Lazy Cook Way’
- Test and item information functions in dexter
- Random variation and power in profile plots
- The scoring game
- dexter meets PISA - The market basket approach
- dexter meets PISA - The basic skills
- Distractor plots in dexter
- dexterMST: dexter for Multi-Stage Tests
- Comparing parameter estimates from dexter
- Equating a pass-fail score with dexter
- Item-total regressions in dexter
- dexter is 1!
- Hello!
Verbal aggression for profit and fun
Young psychometricians often cast a curious, if not envious, glance towards what is now called machine learning. The feeling is mutual: machine learning people, especially those dealing with two-way problems (recommender systems…), have found inspiration in psychometric techniques such as the factor model or the Rasch model. In what follows, I will apply some of my favourite (and not so favourite) multivariate techniques to the now famous verbal aggression data set. There will be relatively more interest in the items than in the persons, although both matter in our discipline. I will show how to get similar results with different techniques, and utterly different results with the same technique. The verbal aggression data (Vansteelandt (2000)) is included with dexter. It is not a cognitive test. 24 items have been produced by the Cartesian product of three facets: * Four embarrassing situations likely to produce an angry reaction. Two of these are caused by others: ‘A bus fails to stop for me’; ‘I miss a train because a clerk gave me faulty information’, and two by self: ‘The grocery store closes just as I am about to enter’; ‘The operator disconnects me when I had used up my last 10 cents for a call’
‘DIF plots again: A correction’
A post or two ago I proposed a clustered heatmap as an optimal
graphical representation of the item pair DIF statistics in
dexter. While the plots are helpful and easy to read,
they are still not exactly what I wanted. The code within the
pheatmap package first computes a distance matrix of
the inputs and then performs cluster analysis, while I argue that the
differences (called Delta_R in the dexter object and
distances here) are distances in themselves. Working with the
distances between the distances is a bit far-fetched so, to get what I
originally wanted, we simply replace dist(dist) with
as.dist(dist). With that change and some adjustment to the
plot when what="distances", the code now becomes:
DIFplot = function(d,
what=c('distances','statistics','pvalues','significance'),
pam=c("none", "holm", "hochberg", "hommel", "bonferroni", "BH", "BY",
"fdr"), cluster = TRUE, alpha=0.05, ...) {
what = match.arg(what)
pam = match.arg(pam)
alpha = alpha/2
dist = abs(d$Delta_R)
o = hclust(as.dist(dist))$order
lbl = d$items$item_id
stat = abs(d$DIF_pair)
outl = lbl[o]
if (cluster) {stat=stat[o,o]; lbl=lbl[o]}
pval = 1 - pnorm(stat)
u0 = pval[lower.tri(pval)]
u1 = p.adjust(u0, method=pam)
pval[lower.tri(pval)] = u1
if(what=='distances') {
if (cluster) { dist = dist[o,o] }
rownames(dist) = colnames(dist) = lbl
diag(dist) = NA
pheatmap::pheatmap(dist, main='PDIF: raw differences', cluster_rows=FALSE, cluster_cols=FALSE)
}
if(what=='statistics') {
rownames(stat) = colnames(stat) = lbl
diag(stat) = NA
pheatmap::pheatmap(stat, main='PDIF: standardized differences', cluster_rows=FALSE, cluster_cols=FALSE)
}
if(what=='pvalues') {
rownames(pval) = colnames(pval) = lbl
diag(pval) = NA
ttl = 'PDIF: p-values'
if (pam != 'none') ttl=paste0(ttl, ' (below diagonal adjusted by ',pam,')')
pheatmap::pheatmap(pval,
main = ttl,
cluster_rows=FALSE, cluster_cols=FALSE,
color = colorRampPalette(RColorBrewer::brewer.pal(n=7, name="RdYlBu"))(100))
}
if(what=='significance') {
ttl = paste0('PDIF: significance at alpha=',2*alpha)
if (pam != 'none') ttl=paste0(ttl, ' (b/d adjusted by ',pam,')')
v = (0 + (pval<alpha))
rownames(v) = colnames(v) = lbl
diag(v) = NA
pheatmap::pheatmap(v, main=ttl, cluster_rows=FALSE, cluster_cols=FALSE, legend=FALSE)
}
return(outl)
}
Trying to extend DIF plots
DIF being such an evergreen, I tried to develop on the nice heatmap we have in dexter. Using the dichotomized version of the verbal aggression data, the current version produces the following:
library(dexter)
dich = dexter::verbAggrRules
dich$item_score[dich$item_score==2] = 1 # dichotomize the items
db = dexter::start_new_project(dich, ":memory:",
person_properties=list(gender="unknown"))
dexter::add_booklet(db, dexter::verbAggrData, "agg")Happy 2024!
 A bit late this year… Too much bubbly?
A bit late this year… Too much bubbly?
dexter in the academic world
 dexter
finally has an academic paper all to and about himself! Get it here in PDF.
dexter
finally has an academic paper all to and about himself! Get it here in PDF.

Minorization and the 2PL
There is an interesting publicly available dataset that has become a bit of a hobby project for me. The data takes some cleaning and restructuring which we may describe in the future. The interesting thing is that a largish set of math and reading items has been administered to a very diverse sample of students, ranging from the final grade of primary education (11-12 year olds), secondary (15-18 yo) and tertiary education (18-19 yo), 14369 persons and 280 items in total. There was some differentiation in that the easiest items were not administered in the highest grades and vice versa. But, as you can imagine, rather than showing a univariate smooth and steady increase of ability through the educational system, this resulted in the motherload of all DIF, not unlike PISA. We will use the mathematics part of this dataset. I wanted to try a factor analysis to see if there were any interesting differences in the underlying make-up of ability between the sectors. Unfortunately, there are no item properties available so we don’t know which items are about geometry or algebra, if there was or was not a context, a graph, etcetera. Therefore we are left with only the possibility for an exploratory factor analysis. Because the data is very incomplete, we need to use an IRT model. The best known option is mirt (Chalmers 2012). Before trying a multi factor model I decided to try a one factor solution to see how well that went. Factor analysis with just one factor is equivalent to the standard 2PL model, which I could compare against our own package dexterMML. I noted some differences in the estimates. These point to one of the difficulties one can encounter when calibrating a 2PL that merit a further look, which is what this story will be about. # Minorization and the 2PL Fitting a 2PL on this dataset takes 2.2 seconds in dexterMML and 22:17 minutes in mirt, but we know dexterMML is relatively fast for incomplete data and in this case every student only did about 10% of the items. Still, the difference is several orders of magnitude and a little concerning since the main cause seems to be that mirt failed to converge.
Psychometric woes (with the 2PL in particular)
It is claimed that the Rasch model does not fit very well, and that it has to be improved for this reason. Improvement is typically seen as adding parameters to the equation of the trace line for each item. The 2PL model gives each trace line a different slope for extra flexibility, the 3PL model tries to be more realistic by introducing a non-zero lower asymptote for random guessing, the 4PL model adds an upper asymptote for random slipping, and so on. The price to pay is dubious mathematical properties of the models and highly unacceptable scoring rules. Already the 3PL model is known to be unidentified, estimation of the asymptotes often needs to be helped with tricks that largely predetermine the outcomes, and the scoring rule punishes everyone for guessing, regardless of whether they guessed or not. I won’t even consider the 4PL model but I will try to demonstrate that the 2PL model is possibly the worst choice for high stakes assessment because it fares particularly badly in terms of both fit and fairness. First we need to agree on what we mean by fit and what we mean by fairness. If we give up as many degrees of freedom as there are items, goodness of fit as measured by some chi squared statistic is bound to increase – sometimes trivially, sometimes not. I would like to know more. Item for item, where does the model fit: all over the ability continuum, in the lower part, in the upper part, or perhaps in the middle where the vast majority of examinees are to be found? These are all questions well answered by the item-total regressions produced by dexter. A good way to approach fairness is by drawing parallels with some other areas where it is of paramount importance, such as sports. Every sports federation has a thick book of rules that try to cover all imaginable situations before any contest has even started. They might say, for example, that athletes may compete barefoot or wearing one or two shoes, and then devote a few pages to the definition of what constitutes acceptable shoes. Testing does have rules of this kind but they apply mostly to the testing situation: may examinees use pocket calculators? What if they need to go to the toilet? How do we detect and handle cheating? But if we take the 2PL model seriously, the most important rule: how much credit is given for answering any particular item correctly, is only determined after the test is over and the data has been collected and processed. Even worse, we cannot give a clear answer why one item should give three times more credit than some other item – because we don’t know ourselves. We can’t tell a highly discriminating item from a less discriminating one by its content alone, the way we can distinguish between easy and hard items. Item writers cannot produce items with low or high discrimination if asked to. Among several explanations (or guesses) as to why the estimated discrimination parameters in a 2PL model differ, arguably the most popular one is that the test is not perfectly unidimensional. However, we usually have no clear idea about the dimensions, and trying to read them off from the item parameter estimates is a bit like predicting the future from coffee sediments. I will propose my own guess about what can make the estimated discrimination parameters in a 2PL model different, and I will test it with simulated data. My theory is quite simple and, I believe, realistic:
Just a Linux rant
I am having a bad day, dear readers. People seem to all run into me, or try to knock me down with their bicycles, or stand in the way, or whatever. A million times. So I will rant on some Linux-related topics for a while, and at the end I will say something about installing dexter and dextergui on Ubuntu Linux for the first time. Those in a hurry please scroll down. Good or bad, it is a great day for me because I finally got rid of a Linux distribution called Elementary OS. Hallelujah! I installed it because it promised to look and feel like MacOS – not that I am so partial to Apple but my taste in design seems to have much in common with that of Steve Jobs and, of course, of Dieter Rams. But Elementary OS! As it is based on Ubuntu but not an official clone, it lags behind the latest versions. Various things did not work properly – most recently, the sound broke. But the most horrid thing about it is the “installation process”. Everyone who has updated Ubuntu recently knows that it is a breeze. Your home folder is preserved, and so is the software that you have installed. With that sort of expectation, I was disappointed to discover that Elementary OS insists on wiping any previous version entirely and starting from scratch. So far so good, but then it failed to recognize the main disc of a brand new computer and happily installed itself on a huge external USB hard drive without the hint of a warning, killing all data on it in the process! I am now running Ubuntu Budgie, which is 22.04 LTS, runs beautifully, and it is a pleasure to look at. Don’t tell me that it is not important – otherwise we would not decorate our homes and would still live in cages.
Simulating data from the interaction model
In a recent post, Jesse has given a somewhat involved example of simulating Rasch / PCM data with dexter. In spite of the rather complex design involving planned missingness and adaptivity, the models at the heart of it are well-known. In this post, we show how to simulate from Haberman’s interaction model (Haberman (2007)), which is very interesting, quite useful in practice, and to our knowledge only available in dexter. And, as an Easter promotion, we give you two methods for the price of one: one based on rejection sampling (dexter’s ‘official’ version), and one based on sampling without rejection. But we start with a short discussion of this fascinating IRT model. ## The interaction model While not even mentioned at the career award session dedicated to Shelby Haberman at NCME 2019, his interaction model (IM) must be one of the brightest, practically most salient ideas in psychometrics since 2000. It plays a strategic role in dexter, and we have posted several times about it and will continue to do so in the future. The IM can be represented in several ways, each of them highlighting different aspects of interest and applicability: * as a generalization of the Rasch model that relaxes conditional independence while retaining sufficient statistics and the immediate connection to the observable
When CML is not possible
Recently, we published a new package dexterMML to the dexter github site, it will probably also be available from CRAN at some time in the future. What follows is the package vignette as it is at the time of writing. In dexter we use an extended (polytomous) Rasch model to equate test forms and classical test analysis, distractor plots and the interaction model for quality control of items. For calibration of the NRM and interacton model we can use conditional maximum likelihood (CML). CML calibration is not possible for fully adaptive tests or for Multi Stage tests with probabilistic routing rules. CML is currently also impractical for random tests (i.e. tests with items randomly selected from a bank). Classical analysis is also not feasible in these situations. So in these cases we must turn to Marginal Maximum Likelihood (MML) where we can use a marginal Rasch model (1PL) for equating and a 2PL for quality control of the items. As the name implies, in MML estimation the likelihood that is maximized is marginal, over an assumed distribution of ability. The likelihood for a response vector for a single person is defined as:
Simulating data with dexter: a commented example
We are busy people. We spend most of our time analyzing the large-scale national and international assessments for which dexter was developed. So far, we have not had the time to discuss at length the facilities for simulating item response data with dexter. Of course they are there, since simulation plays a vital role in our approach to generating plausible values and modelling in general – see Marsman et al. (2017). But they are somewhat hidden among several ‘functions of theta’ – anyway, here is the overdue introduction to data simulation with dexter. Simulating IRT data for a single booklet of Rasch items is quite easy – it can be done with a single line in plain R:
Approximate survey errors for the correlation and the standard deviation: with R package survey
For a survey statistician, there can hardly be anything more helpful
than Thomas Lumley’s survey Lumley
(2010). Not surprisingly, it has been downloaded over 3.1 million
times at the time of writing, which makes it one of the more popular
packages for R (R Development Core Team
2005). Unfortunately, survey does not have functions
to estimate two popular statistics, the standard deviation and the
Pearson correlation, and their standard errors. Packages like
srvyr (Freedman Ellis and Schneider
2021) or jtools (Long
2020) have attempted to fill this lacune, but they only provide
the estimates, not the standard errors. Consider an object,
est, containing survey estimates for the
variances of three variables. The variables happen to be plausible
values (Marsman et al. 2016) from a large
educational survey, and the estimates have been produced by a
replication method (BRR, see Lumley
(2010), Ch.2.3). Note that I could have had any variables instead
of plausible values (remember petal length? sepal width?), and that we
are discussing the standard error under repeated sampling form a
population. The question about the meaning of the correlation between
two sets of plausible values, or the variability seen in a whole bunch
of them, is psychometrically relevant, but it will be discussed in a
different post. Applying the generic print method, I get:
Classical Test Theory with IRT
There is a long-standing interest in combining item response theory
(IRT) and classical test theory (CTT) rather than treat them as mere
alternatives (Bechger et al. 2003). The
theta functions in dexter are particularly helpful in
this approach: - expected_score(): The expected score given
theta. - information(): The Fisher information about theta
in the test score. - p_score(): The distribution of test
scores given theta.
Happy 2022!
 Merry Christmas and a happy, healthy and
prosperous 2022 to all! There have not been many changes to
dexter in 2021, but overall it has been a happy year,
professionally, and we have many ideas for the near future.
dexter is known in 145 countries now. It has taken 5
months to get from 140 to 145, so it may be a while until the next
increase. Prize question: which density function approximates best the
unique shape of Dexter’s ear?
Merry Christmas and a happy, healthy and
prosperous 2022 to all! There have not been many changes to
dexter in 2021, but overall it has been a happy year,
professionally, and we have many ideas for the near future.
dexter is known in 145 countries now. It has taken 5
months to get from 140 to 145, so it may be a while until the next
increase. Prize question: which density function approximates best the
unique shape of Dexter’s ear?
140!
Just a few lines to boast that (i) dexter has been
downloaded in 140 countries now, and (ii) that I have learned how to
make nice maps with tmap and leaflet.

And have you seen the Rasch sampler?
Our most distinguished colleague, Norman D. Verhelst, had his birthday a couple of days ago. As a tiny tribute, I offer a lecture I gave a couple of months ago to a bunch of students. They had moderate exposure to statistics, and I have edited it somewhat hastily, so the level is not particularly uniform — sorry, folks. The RaschSampler (Verhelst et al. 2007) is an R package that allows the user to test a vast array of statistical hypotheses about the Rasch model. It is also a good example of how the statistical testing of hypotheses works, especially in its nonparametric variety. The theory behind the RaschSampler seems to go back to Georg Rasch himself. In a nutshell: Since the row sums and the column sums in a 0/1 matrix are sufficient statistics for the person parameters and the item parameters in the Rasch model, correspondingly, then any other matrix having the same marginal sums will be just as compatible with the Rasch model in terms of measurement. If we compute a statistic of interest on all matrices having the same marginal sums as our observed matrix, then we can place the statistic for the observed matrix in the distribution of all statistics. The statistic itself can be anything: if you compute the matrix of tetrachoric correlations between all items, divide its seventh eigenvalue by the first, take the log and multiply it by Boltzmann’s constant, it would still work (now, try and derive the asymptotic distribution of this statistic). Of course, we would like to use sensible statistics — Ponocny (2001) gives many useful examples. And we wouldn’t like to work with all matrices having the same marginal sums, because there are so many of them. But, if we can have a program that produces, efficiently, a representative sample of them, the practical interest is obvious. The key to the problem was given by Verhelst (2008).

Analyzing continuous responses with dexter
When we apply IRT to score tests, we most often use a model to map patterns of TRUE/FALSE responses onto a real-valued latent variable, the great advantage being that responses to different test forms can be represented on the same latent variable relatively easy. When all observed responses are continuous, most psychometricians will probably think first of factor analysis, structural equations and friends. Yet the world of IRT is more densely populated with continuous responses than anticipated. To start with, computer-administered testing systems such as MathGarden readily supply us with pairs of responses and response times. It is a bit awkward to model them simultaneously, since responses are usually discrete (with few categories) and response times continuous – yet there exist a myriad of models, as the overview in Boeck and Jeon (2019) shows. To apply the same type of model to both responses and response times, Partchev and De Boeck (2012) have chosen to split the latter at the median, either person- or item-wise. Second, item responses increasingly get scored by machine learning algorithms (e.g. Settles et al. (2020)), whose output is typically a class membership probability. If classification is to be into two classes, the boundary is usually drawn at 0.5. One of the questions we ask ourselves in this blog is whether there can be a better way. Within more traditional testing, there have been attempts to avoid modeling guessing behavior with ad hoc models by asking test takers about their perceived certainty that the chosen response is correct (Finetti (1965), Dirkzwager (2003)). These approaches also lead to responses that can be considered as continuous.
Round about SVD
I have been trying to explain to a bunch of psychometricians some points about singular value decomposition (SVD) and its uses in data analysis. It turned out a bit difficult – not because the points are complicated but because psychometricians seem to be imprinted with principal components analysis (PCA), one possible technique related to SVD. There are many more possibilities to explore. The data set in which I was originally interested is a bit large and complicated, so in this tutorial I will use the famous iris data (sorry, guys). Everybody knows and loves the iris data, especially the first 100 times they saw it analyzed. There are three species, or is it subspecies, of this beautiful flower, and a kind soul has measured four different lengths on 50 specimens of each. 150 flowers is a bit too much for my purpose, so I will use just the first ten specimens of each kind. The data is now small enough to show in its entirety:
Sepal.Length |
Sepal.Width |
Petal.Length |
Petal.Width |
Species |
|---|---|---|---|---|
5.1 |
3.5 |
1.4 |
0.2 |
setosa |
4.9 |
3.0 |
1.4 |
0.2 |
setosa |
4.7 |
3.2 |
1.3 |
0.2 |
setosa |
4.6 |
3.1 |
1.5 |
0.2 |
setosa |
5.0 |
3.6 |
1.4 |
0.2 |
setosa |
5.4 |
3.9 |
1.7 |
0.4 |
setosa |
4.6 |
3.4 |
1.4 |
0.3 |
setosa |
5.0 |
3.4 |
1.5 |
0.2 |
setosa |
4.4 |
2.9 |
1.4 |
0.2 |
setosa |
4.9 |
3.1 |
1.5 |
0.1 |
setosa |
5.0 |
2.0 |
3.5 |
1.0 |
versicolor |
5.9 |
3.0 |
4.2 |
1.5 |
versicolor |
6.0 |
2.2 |
4.0 |
1.0 |
versicolor |
6.1 |
2.9 |
4.7 |
1.4 |
versicolor |
5.6 |
2.9 |
3.6 |
1.3 |
versicolor |
6.7 |
3.1 |
4.4 |
1.4 |
versicolor |
5.6 |
3.0 |
4.5 |
1.5 |
versicolor |
5.8 |
2.7 |
4.1 |
1.0 |
versicolor |
6.2 |
2.2 |
4.5 |
1.5 |
versicolor |
5.6 |
2.5 |
3.9 |
1.1 |
versicolor |
6.3 |
3.3 |
6.0 |
2.5 |
virginica |
5.8 |
2.7 |
5.1 |
1.9 |
virginica |
7.1 |
3.0 |
5.9 |
2.1 |
virginica |
6.3 |
2.9 |
5.6 |
1.8 |
virginica |
6.5 |
3.0 |
5.8 |
2.2 |
virginica |
7.6 |
3.0 |
6.6 |
2.1 |
virginica |
4.9 |
2.5 |
4.5 |
1.7 |
virginica |
7.3 |
2.9 |
6.3 |
1.8 |
virginica |
6.7 |
2.5 |
5.8 |
1.8 |
virginica |
7.2 |
3.6 |
6.1 |
2.5 |
virginica |
The information game
A typical task in adaptive testing is to select, out of a precalibrated item pool, the most appropriate item to ask, given an interim estimate of ability, . A popular approach is to select the item having the largest value of the item information function (IIF) at . When the IRT model is the Rasch model, the item response function (IRF) is where is the item difficulty, and the IIF can be computed as . For all items, this function reaches a maximum of 0.25, encountered exactly where and . So picking the item with the maximum IIF is the same as picking the item for which a person of ability of has a probability of 0.5 to produce the correct answer. If we use the two-parameter logistic (2PL) model instead, the IRF is where the new parameter is called the discrimination parameter, and the IIF can be computed as . Note that while the contribution of the product, , remains bounded between 0 and 0.25, the influence of can become quite large – for example, if , gets multiplied by 25, ten times the maximum value under the Rasch model. Selecting such an informative item gives us the happy feeling that our error of measurement will decrease a lot, but what happens to the person’s probability to give the correct response? In our game, we have one person and two items. The person’s ability is 0, represented with a vertical gray line. One of the item is fixed to be a Rasch item with ; its IRF is shown as a solid black curve, and its IIF as a dotted black curve. The second item, shown in red, is 2PL, and you can control its two parameters with the sliders. Initially, and .
Calculating the score distribution given ability
[A muggle preface by Ivailo] As every fantasy lover knows, IRT
people belong to two towers, or is it schools of magic. The little
wizards and witches of one school learn to condition on their sufficient
statistics before they can even fly or play quidditch, while at the
other school they will integrate out anything thrown at them.
The two approaches have their subtle differences. To predict the score
distribution conditional on ability, wizards at the first school apply
the same powerful curse, elementary symmetric functions, that they use
for all kinds of magic – from catching dragons over estimating
parameters, up to item-total and item-rest regressions, to mention but a
few. At the second school, computing the score distribution used to be a
frustrating task until Lord and Wingersky
(1984) came up with a seemingly unrelated jinx that did the
trick. In what follows, Timo explains how the two kinds of magic relate
to each other. Consider the Rasch model. Let
denote the binary-coded response to item
and assume that:
Local (in)dependence and polytomization
dexter has a function, fit_domains, that
deals with subtests. Domains are subsets of the items in the test
defined as a nominal variable: an item property. The items in each
subset are transformed into a large partial credit item whose item score
is the subtest score; the two models, ENORM and the interaction models,
are then fit on the new items. To illustrate, let us go back to our
standard example, the verbal aggression data. Each of the 24 items
pertains to one of four frustrating situations. Treating the four
situations as subtests or domains, we obtain for one of them:
 To the left we see how the two models compare in predicting the category
probabilities; to the right are the item-total regressions for the item
(i.e. domain) score. Everything looks nice for this high-quality data
set, but note in particular how closely the two models agree for the
domain score. For all four situations:
To the left we see how the two models compare in predicting the category
probabilities; to the right are the item-total regressions for the item
(i.e. domain) score. Everything looks nice for this high-quality data
set, but note in particular how closely the two models agree for the
domain score. For all four situations:
My (more or less coherent) views on model fit
Your psychometric model should fit the data, they keep telling me, or else you are in trouble. I find the idea bizarre. I am certainly not out there to explain the exam with a model, I just want to grade it. My (Rasch) model fits the scoring rule, and it is there basically to serve as an equating tool for multiple test forms, an alternative to equipercentile or kernel equating. If I am modeling anything, it is not the data but a particular social situation: mutual agreement that the sum score is a reasonable, acceptable, sensible, optimal way to grade the exam. Some theory but, ultimately, decades of collective experience keep me convinced that the model will also generally fit the data, as there is precious little useful information that is not already in the sum score. After all, the test was made this way. Hence, in the realm of practical testing (as opposed to research, which is a different story altogether), item fit is primarily a quality control thing. If an item has no correlation with the sum score, it is badly written. If the correlation is negative, the scoring key is wrong. Such situations can usually be identified and corrected quite easily. When the items are decently written and correctly scored, the Rasch model will fit the data in grosso modo, and differences in discrimination will cancel – certainly at test level but possibly even when we put together a small number of items as a subscale. ## How to measure As a quality control measure or otherwise, it is of course a good idea to look at item fit. In dexter, our preferred approach is a visual inspection of the item-total regressions. These provide a detailed picture of fit over the whole ability range, involving the observed data, the calibration model, and the interaction model. An overall number might be useful, if anything, to sort the plots for the individual items, such that we look at the worst (or best) fitting items first.

fyi
I have just received an email labelled fyi from our new maintainer. From it I deduce that a new version of dexter is on CRAN. I count three new features, two improvements, and three bug fixes. You may want to check it out, as I most certainly will.
‘dexter is 1 — again!’
 Back in February 2018, we wrote about the first birthday of
dexter. Our little dear has now reached yet another
stage of maturity: dexter 1.0.0 is available on CRAN. A
new version of dextergui to match is on its way. There
are no dramatic changes or additions, but the whole package has been
revised, and all non-R parts rewritten in C++ for improved consistency
and yet more speed! And even the remotest corners have been cleaned by
the new maintainer, Jesse Koops, in the most
Back in February 2018, we wrote about the first birthday of
dexter. Our little dear has now reached yet another
stage of maturity: dexter 1.0.0 is available on CRAN. A
new version of dextergui to match is on its way. There
are no dramatic changes or additions, but the whole package has been
revised, and all non-R parts rewritten in C++ for improved consistency
and yet more speed! And even the remotest corners have been cleaned by
the new maintainer, Jesse Koops, in the most obsessive
thorough way. Same package, totally new experience.
120-100-100!
I have just put this nice picture on one of the social networks.
dexter, our R package for psychometric analysis of
tests, has been downloaded in 120 different countries now. And each of
the companion packages, dexterGUI and
dexterMST, have been downloaded in 100 countries!
Thanks to authors and users alike! 
My perennial Slide 1
I have found out that, regardless of the immediate topic, it is usually
easiest and most helpful to start my talks with the same slide. It shows
a primitive roadmap of our discipline, like this:
 Nothing that you didn’t know. I knew it too, but it took me quite a
pilgrimage to develop a feel for how important it is, to realize that
the criteria for what is desirable, appropriate or even admissible are
largely local. Now, that matters a lot. In assessment, we are focused on
the individual. Regardless of how much statistical thinking is involved,
it remains essentially idiographic. In producing a score for the
individual, we try to remove as much uncertainty as possible –
typically, we go for the central tendency of the person’s ability
distribution, not for a random sample from it. Research has an extra
statistical layer, being interested primarily in populations rather than
individuals. Substantive research, which I see mostly in the shape of
large-scale studies, is deeply concerned with two sampling processes:
reproducing a finite population of individuals, which involves sampling
methods and designs, variance estimation, sampling weights and the like;
and sampling from the individual ability distributions with a realistic
representation of their variability – in other words, reliance on
plausible values and scores.
Nothing that you didn’t know. I knew it too, but it took me quite a
pilgrimage to develop a feel for how important it is, to realize that
the criteria for what is desirable, appropriate or even admissible are
largely local. Now, that matters a lot. In assessment, we are focused on
the individual. Regardless of how much statistical thinking is involved,
it remains essentially idiographic. In producing a score for the
individual, we try to remove as much uncertainty as possible –
typically, we go for the central tendency of the person’s ability
distribution, not for a random sample from it. Research has an extra
statistical layer, being interested primarily in populations rather than
individuals. Substantive research, which I see mostly in the shape of
large-scale studies, is deeply concerned with two sampling processes:
reproducing a finite population of individuals, which involves sampling
methods and designs, variance estimation, sampling weights and the like;
and sampling from the individual ability distributions with a realistic
representation of their variability – in other words, reliance on
plausible values and scores.
Temporary issues with predicates, and how to resolve
Predicates are a useful and powerful feature in dexter allowing users to filter the data passed to almost any function on arbitrarily complex combinations of the variables in the data base. Depending on the package infrastructure, some users may have experienced problems with predicates recently. This is caused by changes in the most recent version of a dependency, dbplyr 1.4. We are talking to the developers of dbplyr. In the meanwhile, problems can be avoided by downgrading dbplyr to version 1.3. Start a new R session and execute:
remove.packages(dbplyr)
library(devtools)
install_version("dbplyr", version="1.3.0")Aspects of the aspect ratio
In my post on DIPF from yesterday, I had plots with an arbitrary
aspect ratio chosen automatically by R. Rather than change them behind
the scenes, I revisit them because I feel the issue deserves attention.
To start with the MDS plot: it is supposed to reconstruct a map from a
distance matrix, so there is no discussion that the aspect ratio should
be set to 1 by adding asp=1 to the arguments of the
plot function. Like this:
‘Visualising Differential Item Pair Functioning: The Lazy Cook Way’
Bechger and Maris (2015) pointed out that, the way DIF is defined in psychometrics, it can be more sensibly related to pairs of items than to the individual item. Starting from the idea that all relevant information can be captured in the (group-specific) distance matrix between item difficulties, I try to visualise the subtle differences between a relatively large number of such distance matrices. This is an improvised meal using products already in the fridge, instant dinner, kitchen express. I am sure it can be vastly improved. First, how do we measure the similarity between two distance matrices? A look at the cuisine of other peoples, notably ecologists, reminds us of the Mantel test. This should not be confused with the Mantel-Haenszel statistic prominent in traditional DIF methodology: a chi-squared test testing the hypothesis that an odds-ratio between two dichotomous variables estimated across the levels of a third discrete variable is significantly different from 1. No, the Mantel test computes, simply, Pearson’s correlation between the two distance matrices, taken as vectors. What is not so simple is establish the statistical significance of the result. Distances are not independent (changing even one would distort the map), so Mantel devises a permutation-based method. I happily ignore that because I am searching for a proximity matrix, not tests of significance. Ingredients: * A PISA data set – I used 2012 Mathematics, available here
dexter 0.8.5 on CRAN
The title says it all, and here are some details from the NEWS file: *
new function design_info() returns extensive information
about incomplete test designs. Functions
design_as_network() and design_is_connected()
are deprecated. * correction for a bug which caused NA’s in plausible
values for booklets with 1 respondent and nPV>1
dexter 0.8.4 is out
I have just uploaded version 0.8.4 of dexter. It has the same functionality as version 0.8.3 except for some minor changes to accommodate the upcoming version of tibble.
Happy 2019!
On behalf of the dexter team, best wishes for a happy, healthy and prosperous New Year to all our users! They seem to be in 113 countries for dexter, 87 countries for dextergui, and 80 countries for dexterMST, according to the current Rstudio stats. I look at these numbers with awe, and I am sure we’ll all keep giving our best!
Test and item information functions in dexter
In an enormously influential short paper, Embretson (1996) sums up five most important
differences between classical test theory (CTT) and item response theory
(IRT). The first among them is that, in CTT, the standard error of
measurement applies to all scores in a particular population, while in
IRT the standard error of measurement differs across scores, but
generalizes across populations. To see how this works, we first take a
leisurely, informal look at some simple examples with the Rasch model;
we then examine the information functions more formally, and we explain
how they are implemented in dexter. The Rasch model
predicts that, given an item and its difficulty parameter,
,
the probability of a correct response is a logistic function of ability,
,
namely,
The information function for the same item happens to be
,
so it is, again, a function of
.
Below we show the item response curve (IRF) for the item, i.e., the
function
along with the corresponding item information function (IIF), shown in
red. When
,
;
this is also the point where the IIF peaks, and the maximum is of course
equal to 0.25. 
dexter 0.8.3 on CRAN
We have just published a new version of dexter. Among the new features are functions to compute the test and information functions, and expected scores. Of course, these have always been computed internally, but we had not thought of adding user-level functions. Information functions are quite interesting – expect a special entry on them very soon. Please ignore the short-lived version 0.8.2. It is the same as 0.8.3 except that we found a bug – a very small one, a mere buglet, but we didn’t like its sharp little teeth so it had to go.
Random variation and power in profile plots
Profile plots are a novel graphical display in dexter designed to visualize a certain kind of measurement invariance. A profile plot is useful when there are: * a population classified in two or more groups, * a test with items classified into two groups – let us call them domains, and * a working hypothesis that groups differ in their response to domains, given the same total score on the test.
The scoring game
Meet Tommy Redd and Jimmy Greene, two school friends who are inseparable and only argue about tests. When they take a test, Jimmy Greene always gets the two easiest items correct, while Tommy Redd somehow manages to answer the two hardest ones correctly but falters on the easy ones. Under classical test theory, both get the same total score of 2, and the Rasch model also gives them the same theta value, as shown on the plot in its initial state. This makes Tommy a bit unhappy because he feels that he deserves more credit for solving more difficult items than Jimmy. With the discovery of the 2PL, 3PL, 4PL … models we can fulfil Tommy’s wish or, indeed, any wish. Play with the controls for the slope parameters of the five items to give: * more credit to Tommy * more credit to Jimmy
100!
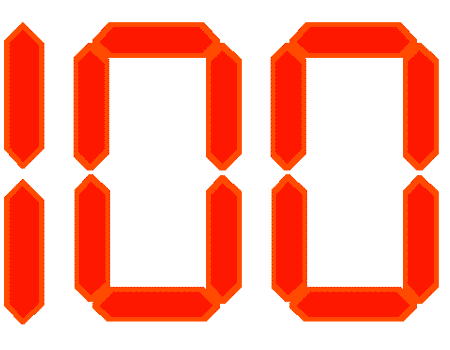 Perhaps not important, but on the other hand
rather overwhelming – according to the Rstudio logs,
dexter has been downloaded in 100 different countries.
Makes one wonder…
Perhaps not important, but on the other hand
rather overwhelming – according to the Rstudio logs,
dexter has been downloaded in 100 different countries.
Makes one wonder…
dexter meets PISA - The market basket approach
In this part, we show how to use dexter to apply the market basket approach (Mislevy 1998) to the mathematics domain in PISA 2012, following the logic in Zwitser et al. (2017). Once we have read in the data and created the dexter database, as shown here, this takes only several lines of code. Still, the article will be a bit longer as the market basket approach deserves some attention on its own. The market basket approach has been borrowed from economics – more precisely, from the study of inflation and purchasing power. To confuse matters further, the machine learning field has appropriated the term to denote something completely different – we can ignore this except that their version is the more likely to show up on top in a Google search. A market basket contains a mix of goods and services in given proportions that, by social consensus, mirrors the prevalent consumption patterns; the cost of obtaining it, in money or work time, can be compared across countries or over time. The idea is simple but the implementation is not trivial. In comparisons over time, the contents of the basket cannot remain constant forever. In the 1970s, your teenager vitally needed a cassette recorder, today it is a smartphone. The commodity that you buy – domestic peace – is the same, but the physical carrier has changed. In comparisons across countries or social groups, one may ask: whose basket? For example, the basket of older people contains mostly food and health care; minimal changes in the prices of these may be barely perceptible for richer, active people, but they may have a large impact on the welfare of the specific group. Because of this, many national statistical services maintain separate price indices for the retired.
dexter meets PISA - The basic skills
We could have issued a WARNING: This bag package is
not a toy! But we can do better. In a series of posts, we will
discuss how to use dexter to analyze data from large
scale educational assessments, such as PISA. The task is a rather
imposing one, not only in the amount of data to be crunched, but mostly
in the number of issues to discuss. In this first part, we will analyze
the mathematics domain in PISA 2012 (OECD
2014). With 65 participating countries, 21 booklets and over half
a million of students, this is anything but a toy example. We will focus
on the basics: how to obtain the data, get it into
dexter, estimate the parameters of the IRT model,
compute plausible values, and apply survey weights and variance
estimation. With these technical aspect under the belt, we can
concentrate on more conceptual issues in further blogs. ## Obtain and
parse PISA data and get it into dexter As of the time of writing, the
following works. We believe that the OECD will keep the data available
forever; however, minute changes in the exact location cannot be
excluded, and that would necessitate changes in the code.
‘dexter 0.8.1 submitted’
We have just submitted dexter 0.8.1 to CRAN. The main difference with regard to 0.8.0 is speed in estimating person abilities. Thanks to C, ML estimation of ability is about 40 times faster than before. Even more important, in absolute gain of time, is the 15x speed up in the computation of plausible values and plausible scores. This could be achieved by implementing the clever recycling algorithms discussed by Maarten Marsman in his PhD dissertation, Plausible Values in Statistical Inference (2014). The speed-up factors cited above are approximate. We have not done a state-of-the-art measurement. In fact, we strongly believe that speed considerations should not be allowed to prevail when discussing methodology. However, when a method has been shown to be optimal in the context of large scale surveys, as is the case with plausible values, and when that method turns out to be computationally intensive, a considerable acceleration does have some relevance. We will return to this in one of the future posts. Other novelties in 0.8.1 are a new plot method for item parameters, and the possibility to read in response data in a format described variously as long, tidy, or normalized.
Distractor plots in dexter
In a previous
post, I wrote about three kinds of item-total regressions available
in dexter: the empirical one, and the smoothed versions
under the Rasch model and the interaction model. In fact, there is one
more item-total regression, available through the
distractor_plot command and the Shiny interfaces in
dexter and dextergui. This will be the
topic today. Unlike the latter two regressions, this one does not
involve a global model for the data (Rasch or interaction model): it is
local. We use the density function in R (R Development Core Team (2005)) to estimate the
density of the total scores twice over the same support: for all
persons, and for the persons who have given a certain response to the
item. Together with the marginal frequency of the response, this is all
we need to apply the Bayes rule and compute the density of the response
given the total score. This is the item-total regression we need. We
call this a distractor plot because we apply it to all possible
responses to the item, including non-response, and not just to the
(modelled) correct response. This provides valuable insights into the
quality of item writing, including trivial annoyances such as a wrong
key. We don’t have to believe that multiple choice items are the
pinnacle of creation but, if we do use them, we must make sure that they
are written well and graded correctly. Good writing means, among other
things, that along with the correct response(s) the item must contain a
sufficient number of sufficiently plausible wrong alternatives
(‘distractors’). Moses (2017) gives a nice
historical overview of the use of similar graphics, from the first
item-total regressions drawn by Thurstone in 1925 to the graphs used
routinely at ETS. He also provides examples (drawn from Livingston and Dorans (2004)) of items that are
too easy, too difficult, or simply not appropriate for a given group of
examinees. Let us also mention the computer program TestGraf98 (Ramsay (2000)) whose functionality has been
reproduced in the R package, KernelSmoothIRT (Mazza et al. (2014)).
dexterMST: dexter for Multi-Stage Tests
dexterMST is a new R package acting as a companion to dexter (Maris et al. 2018) and adding facilities to manage and analyze data from multistage tests (MST). It includes functions for importing and managing test data, assessing and improving the quality of data through basic test and item analysis, and fitting an IRT model, all adapted to the peculiarities of MST designs. It is currently the only package that offers the possibility to calibrate item parameters from MST using Conditional Maximum Likelihood (CML) estimation (Zwitser and Maris 2015). dexterMST will accept designs with any number of stages and modules, including combinations of linear and MST. The only limitation is that routing rules must be score-based and known before test administration. ## What does it do? Multi-stage tests (MST) must be historically the earliest attempt to achieve adaptivity in testing. In a traditional, non-adaptive test, the items that will be given to the examinee are completely known before testing has started, and no items are added until it is over. In adaptive testing, the items asked are, at least to some degree, contingent on the responses given, so the exact contents of the test only becomes known at the end. (Bejar 2014) gives a nice overview of early attempts at adaptive testing in the 1950s. Other names for adaptive testing used in those days were tailored testing or response-contingent testing. Note that MST can be done without any computers at all, and that computer-assisted testing does not necessarily have to be adaptive. When computers became ubiquitous, full-scaled computerized adaptive testing (CAT) emerged as a realistic option. In CAT, the subject’s ability is typically reevaluated after each item and the next item is selected out of a pool, based on the interim ability estimate. In MST, adaptivity is not so fine-grained: items are selected for administration not separately but in bunches, usually called modules. In the first stage of a MST, all respondents take a routing test. In subsequent stages, the modules they are given depend on their success in previous modules: test takers with high scores are given more difficult modules, and those with low scores are given easier ones – see e.g., Zenisky et al. (2009), Hendrickson (2007), or Yan et al. (2014).
Comparing parameter estimates from dexter
A critical user of dexter might simulate data and then
plot estimates of the item parameters against the true values to check
whether dexter works correctly. Her results might look
like this:
 After a moment of thought, the researcher finds that she is looking at
item easiness, while dexter reports item difficulties.
After the sign has been reversed, the results look better but still not
quite as expected:
After a moment of thought, the researcher finds that she is looking at
item easiness, while dexter reports item difficulties.
After the sign has been reversed, the results look better but still not
quite as expected:

Equating a pass-fail score with dexter
Educational tests are often equipped with a threshold to turn the test score into a pass-fail decision. When a new test of the same kind is developed, we need a threshold for it that will be, in some sense, equivalent to the threshold for the old — let us call it reference — test. This is a special case of test equating, and it is similar to some well-studied problems in epidemiology; for the comfort of our predominantly psychometric audience, we start with an outline of those. Consider a test for pregnancy. The state of nature is a binary variable (positive / negative). So is the outcome of the test, although the decision is possibly produced by dichotomizing the quantitative measurement of some hormone or other substance, just like we want to do with our educational test scores. There are four possible outcomes in all, which can be represented in a two-by-two table
| State of nature | |||
| Positive | Negative | ||
| Prediction | Positive | True positive (TP) | False positive (FP) |
| Negative | False negative (FN) | True negative (TN) | |
Item-total regressions in dexter
Regression is the conditional expectation of a variable given the value
of another variable. It can be estimated from data, plotted, and modeled
(smoothed) with suitable functions. An example is shown on the figure
below.
 This regression is completely based on observable quantities. On the
x-axis we have the possible sum scores from a test of 18 dichotomous
items. The expected item score on one of the items (actually, the
third), given the sum score, is shown on the y-axis. It is little to say
that item response theory (IRT) is interested in such
regressions: in fact, it is made of them – except that it
regresses the expected item score on a latent variable rather than the
observed sum score. Assuming that each person’s item scores are
conditionally independent given the person’s value on the latent
variable, and that examinees work independently, we multiply what needs
to be multiplied, and we end up with a likelihood function to optimize.
Having found estimates for the model parameters, we would like to see
whether the model fits the data. In a long tradition going back to
Andersen’s test for the fit of the Rasch model, model fit is evaluated
by comparing observed and expected item-total regression functions. The
item-fit statistics in the OPLM software package (corporate software at
Cito developed by Norman Verhelst and Cees Glas), are also of this
nature. But the comparison is not necessarily easy – at least, not for
every kind of model.
This regression is completely based on observable quantities. On the
x-axis we have the possible sum scores from a test of 18 dichotomous
items. The expected item score on one of the items (actually, the
third), given the sum score, is shown on the y-axis. It is little to say
that item response theory (IRT) is interested in such
regressions: in fact, it is made of them – except that it
regresses the expected item score on a latent variable rather than the
observed sum score. Assuming that each person’s item scores are
conditionally independent given the person’s value on the latent
variable, and that examinees work independently, we multiply what needs
to be multiplied, and we end up with a likelihood function to optimize.
Having found estimates for the model parameters, we would like to see
whether the model fits the data. In a long tradition going back to
Andersen’s test for the fit of the Rasch model, model fit is evaluated
by comparing observed and expected item-total regression functions. The
item-fit statistics in the OPLM software package (corporate software at
Cito developed by Norman Verhelst and Cees Glas), are also of this
nature. But the comparison is not necessarily easy – at least, not for
every kind of model.
dexter is 1!
Today is exactly a year since we presented
our R package, dexter, for the first time at the 2017 Psychoco workshop
in Vienna. Having partaken of the birthday cake  , I (Ivailo) now concentrate on this year’s
edition of Psychoco, where I will present a talk on item-total
regressions in dexter. The slides, or a short informal paper, will be
posted here after the workshop. I wish to close, once and for all, the
topic of the package’s name. dexter is named after my
ex-neighbours’ dog
, I (Ivailo) now concentrate on this year’s
edition of Psychoco, where I will present a talk on item-total
regressions in dexter. The slides, or a short informal paper, will be
posted here after the workshop. I wish to close, once and for all, the
topic of the package’s name. dexter is named after my
ex-neighbours’ dog  . I was searching for
an acronym, preferably not mirt (there are at least three programs under
that name already), I looked out of the window, and the name was found.
Unfortunately, I could not take a better picture before they moved out,
but yes, this is the Real Dexter. We have absolutely nothing to do with
that other character.
We meant dexter as in dexterous and dexterity, and the
Urban
Dictionary is also full of praise: >>A sweet, caring, out
going guy that is a good friend. Dexters are good boyfriends.
. I was searching for
an acronym, preferably not mirt (there are at least three programs under
that name already), I looked out of the window, and the name was found.
Unfortunately, I could not take a better picture before they moved out,
but yes, this is the Real Dexter. We have absolutely nothing to do with
that other character.
We meant dexter as in dexterous and dexterity, and the
Urban
Dictionary is also full of praise: >>A sweet, caring, out
going guy that is a good friend. Dexters are good boyfriends.
Hello!
Cito is a Dutch educational testing company founded about 50 years ago and situated in Arnhem. Cito is responsible for a large part of the educational assessments in the Netherlands, participates in numerous international projects such as PISA or ESLC, and offers consultancy around the globe. In a somewhat unprecedented move, Cito have decided to publish their latest psychometric software as open source, even before it is completely finished. The R package, dexter, has been available on CRAN since February 2017, and is currently at version 0.5.4. In this blog, we would like to share news about the software, tutorials, and further information useful to the users. We might also discuss broader topics in educational assessment and its social impact. The views expressed in the blog are our own. dexter is developed at Cito, the Netherlands, with subsidy from the Dutch Ministry of Education, Culture, and Science. Timo Bechger •