Test individual differences
individual_differences(dataSrc, predicate = NULL)Arguments
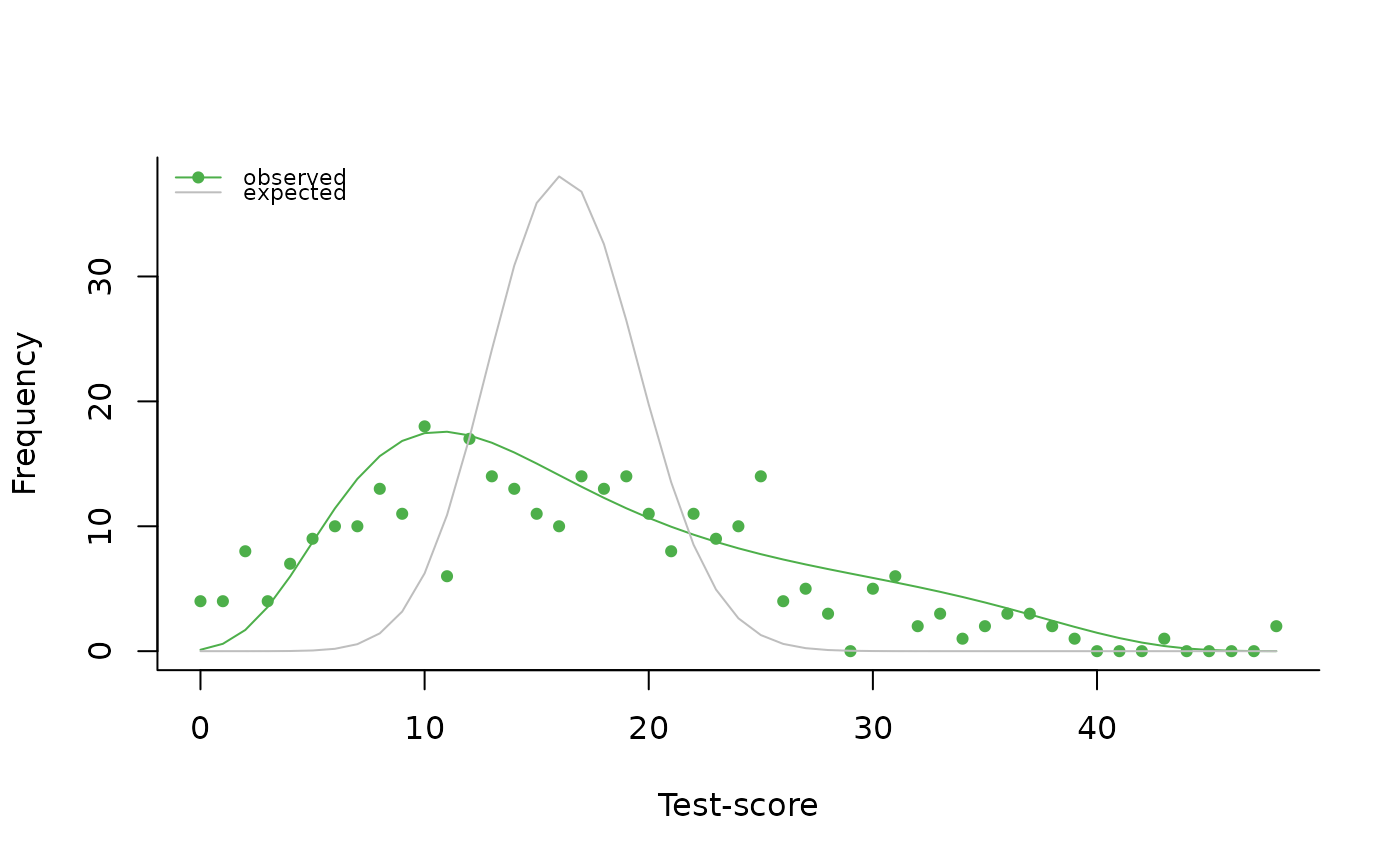
Value
An object of type tind. Printing the object will show test results. Plotting it will produce a plot of expected and observed score frequencies. The former under the hypothesis that there are no individual differences.
Details
This function uses a score distribution to test whether there are individual differences in ability. First, it estimates ability based on the score distribution. Then, the observed distribution is compared to the one expected from the single estimated ability. The data are typically from one booklet but can also consist of the intersection (i.e., the common items) of two or more booklets. If the intersection is empty (i.e., no common items for all persons), the function will exit with an error message.
Examples
db = start_new_project(verbAggrRules, ":memory:")
add_booklet(db, verbAggrData, "agg")
#> no column `person_id` provided, automatically generating unique person id's
#> $items
#> [1] "S1DoCurse" "S1DoScold" "S1DoShout" "S1WantCurse" "S1WantScold"
#> [6] "S1WantShout" "S2DoCurse" "S2DoScold" "S2DoShout" "S2WantCurse"
#> [11] "S2WantScold" "S2WantShout" "S3DoCurse" "S3DoScold" "S3DoShout"
#> [16] "S3WantCurse" "S3WantScold" "S3WantShout" "S4DoCurse" "S4DoScold"
#> [21] "S4DoShout" "S4WantCurse" "S4WantScold" "S4WantShout"
#>
#> $person_properties
#> character(0)
#>
#> $columns_ignored
#> [1] "gender" "anger"
#>
dd = individual_differences(db)
print(dd)
#> Chi-Square Test for the hypothesis that respondents differ in ability:
#>
#> Chi-squared test for given probabilities with simulated p-value (based
#> on 2000 replicates)
#>
#> data: observed
#> X-squared = 1.6144e+21, df = NA, p-value = 0.0004998
#>
plot(dd)
 close_project(db)
close_project(db)